Heart Beat Mechanism
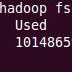
As of now, we know that once if the input file is loaded on to the Hadoop Cluster, the file is sliced into blocks, and these blocks are distributed among the cluster.
Now Job Tracker and Task Tracker comes into picture. To process the data, Job Tracker assigns certain tasks to the Task Tracker. Let us think that, while the processing is going on one DataNode in the cluster is down. Now, NameNode should know that the certain DataNode is down , otherwise it cannot continue processing by using replicas. To make NameNode aware of the status(active / inactive) of DataNodes, each DataNode sends a "Heart Beat Signal" for every 10 minutes(Default). This mechanism is called as HEART BEAT MECHANISM.

Based on this Heart Beat Signal Job Tracker assigns tasks to the Tasks Trackers which are active. If any task tracker is not able to send the signal in the span of 10 mins, Job Tracker treats it as inactive, and checks for the ideal one to assign the task. If there are no ideal Task Trackers, Job Tracker should wait until any Task Tracker becomes ideal.
We can change the default value of Heart Beat Signal (10 minutes), by configuring in "mapred-site.xml".